| Issue |
EPJ Nuclear Sci. Technol.
Volume 4, 2018
Special Issue on 4th International Workshop on Nuclear Data Covariances, October 2–6, 2017, Aix en Provence, France – CW2017
|
|
|---|---|---|
| Article Number | 33 | |
| Number of page(s) | 10 | |
| Section | Covariance Evaluation Methodology | |
| DOI | https://doi.org/10.1051/epjn/2018013 | |
| Published online | 14 November 2018 | |
https://doi.org/10.1051/epjn/2018013
Regular Article
Estimating model bias over the complete nuclide chart with sparse Gaussian processes at the example of INCL/ABLA and double-differential neutron spectra
Irfu, CEA, Université Paris-Saclay,
91191
Gif-sur-Yvette, France
* e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
7
November
2017
Received in final form:
2
February
2018
Accepted:
4
May
2018
Published online: 14 November 2018
Abstract
Predictions of nuclear models guide the design of nuclear facilities to ensure their safe and efficient operation. Because nuclear models often do not perfectly reproduce available experimental data, decisions based on their predictions may not be optimal. Awareness about systematic deviations between models and experimental data helps to alleviate this problem. This paper shows how a sparse approximation to Gaussian processes can be used to estimate the model bias over the complete nuclide chart at the example of inclusive double-differential neutron spectra for incident protons above 100 MeV. A powerful feature of the presented approach is the ability to predict the model bias for energies, angles, and isotopes where data are missing. The number of experimental data points that can be taken into account is at least in the order of magnitude of 104 thanks to the sparse approximation. The approach is applied to the Liège intranuclear cascade model coupled to the evaporation code ABLA. The results suggest that sparse Gaussian process regression is a viable candidate to perform global and quantitative assessments of models. Limitations of a philosophical nature of this (and any other) approach are also discussed.
© G. Schnabel, published by EDP Sciences, 2018
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1 Introduction
Despite theoretical advances, nuclear models are in general not able to reproduce all features of trustworthy experimental data. Because experiments alone do not provide sufficient information to solve problems of nuclear engineering, models are still needed to fill the gaps.
Being in need of reliable nuclear data, a pragmatic solution to deal with imperfect models is the introduction of a bias term on top of the model. The true prediction is then given as the sum of model prediction and bias term. The form of the bias term is in principle arbitrary and a low order polynomial could be a possible choice. However, assumptions about how models deviate from reality are usually very vague, which makes it difficult to justify one parametrization over another one.
Methods of non-parametric statistics help to a certain extent to overcome this specification problem. In particular, Gaussian process (GP) regression (also known as Kriging, e.g., [1]) enjoys popularity in various fields, such as geostatistics, remote sensing and robotics, due to its conceptual simplicity and sound embedding in Bayesian statistics. Instead of providing a parameterized function to fit, one specifies a mean function and a covariance function. The definition of these two quantities induces a prior probability distribution on a function space. Several standard specifications of parametrized covariance functions exist, e.g., [[1], Chap. 4], whose parameters regulate the smoothness and the magnitude of variation of the function to be determined by GP regression.
The optimal choice of the values for these so-called hyperparameters is problem dependent and can also be automatically performed by methods such as marginal likelihood optimization and cross validation, e.g., [[1], Chap. 5]. In addition, features of various covariance functions can be combined by summing and multiplying them. Both the automatic determination of hyperparameters and the combination of covariance functions will be demonstrated.
From an abstract viewpoint, GP regression is a method to learn a functional relationship based on samples of input-output associations without the need to specify a functional shape. GP regression naturally yields besides estimates also the associated uncertainties. This feature is essential for evaluating nuclear data, because uncertainties of estimates are as important for the design of nuclear facilities as are the estimates themselves. Prior knowledge about the smoothness and the magnitude of the model bias can be taken into account. Furthermore, many existing nuclear data evaluation methods, e.g., [2–4], can be regarded as special cases. This suggests that the approach discussed in this paper can be combined with existing evaluation methods in a principled way.
The main hurdle for applying GP regression is the bad scalability in the number of data points N. The required inversion of an N × N covariance matrix leads to computational complexity of N3. This limits the application of standard GP regression to several thousand data points on contemporary desktop computers. Scaling up GP regression to large datasets is therefore a field of active research. Approaches usually rely on a combination of parallel computing and the introduction of sparsity in the covariance matrix, which means to replace the original covariance matrix by a low rank approximation, see e.g., [5].
In this paper, I investigate the sparse approximation introduced in [6] to estimate the model bias of inclusive double-differential neutron spectra over the complete nuclide chart for incident protons above 100 MeV. The predictions are computed by the C++ version of the Liège intranuclear cascade model (INCL) [7,8] coupled to the Fortran version of the evaporation code ABLA07 [9]. The experimental data are taken from the EXFOR database [10].
The idea of using Gaussian processes to capture deficiencies of a model exists for a long time in the literature, see e.g., [11], and has also already been studied in the context of nuclear data evaluation, e.g., [12–14]. The novelty of this contribution is the application of GP regression to a large dataset with isotopes across the nuclide chart, which is possible thanks to the sparse approximation. Furthermore, the way GP regression is applied enables predictions for isotopes without any data.
The exemplary application of sparse GP regression in this paper indicates that the inclusion of hundred thousands of data points may be feasible and isotope extrapolations yield reasonable results if some conditions are met. Therefore, sparse GP regression is a promising candidate to perform global assessments of models and to quantify their imperfections in a principled way.
The structure of this paper is as follows. Section 2 outlines the theory underlying sparse GP regression. In particular, Section 2.1 provides a succinct exposition of standard GP regression, Section 2 sketches how to construct a sparse approximation to a GP and how this approximation is exploited in the computation, and Section 2.3 explains the principle to adjust the hyperparameters of the covariance function based on the data.
The application to INCL/ABLA and inclusive double-differential neutron spectra is then discussed in Section 3. After a brief introduction of INCL and ABLA in Section 3.1, the specific choice of covariance function is detailed in Section 3.2. Some details about the hyperparameter adjustment are given in Section 3.3 and the results of GP regression are shown and discussed in Section 3.4.
2 Method
2.1 GP regression
GP regression, e.g., [1], can be derived in the framework of Bayesian statistics under the assumption that all probability distributions are multivariate normal. Let the vector y1 contain the values at the locations  of interest and y2 the observed values at the locations
of interest and y2 the observed values at the locations  .
.
For instance, in the application in Section 3, the elements in the vector y1 represent the relative deviations of the “truth” from the model predictions for neutron spectra at angles and energies of interest. The vector y2 contains the relative deviations of the available experimental data from the model predictions for neutron spectra at the angles and energies of the experiments. The underlying assumption is that the experimental measurements differ from the truth by an amount compatible with their associated uncertainties. If this assumption does not hold, model bias should be rather understood as a combination of model and experimental bias.
Given a probabilistic relationship between the vectors y1 and y2, i.e. we know the conditional probability density function (pdf) of y2 given y1, ρ(y2|y1) (e.g., because of continuity assumptions), the application of the Bayesian update formula yields
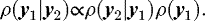 (1)
(1)
The occurring pdfs are referred to as posterior 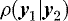 , likelihood
, likelihood 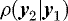 , and prior
, and prior 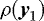 . The posterior pdf represents an improved state of knowledge.
. The posterior pdf represents an improved state of knowledge.
The form of the pdfs in the Bayesian update formula can be derived from the joint distribution 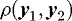 . In the following, we need the multivariate normal distribution
. In the following, we need the multivariate normal distribution
 (2)
which is characterized by the center vector μ and the covariance matrix K. The dimension of the occurring vectors is denoted by N. Under the assumption that all pdfs are multivariate normal and centered at zero, the joint distribution of y1 and y2 can be written as
(2)
which is characterized by the center vector μ and the covariance matrix K. The dimension of the occurring vectors is denoted by N. Under the assumption that all pdfs are multivariate normal and centered at zero, the joint distribution of y1 and y2 can be written as
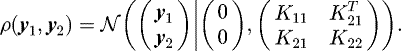 (3)
(3)
The compound covariance matrix contains the blocks K11 and K22 associated with 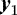 and y2, respectively. The block K21 contains the covariances between the elements of y1 and y2. Centering the multivariate normal pdf at zero is a reasonable choice for the estimation of model bias. It means that an unbiased model is a priori regarded as the most likely option.
and y2, respectively. The block K21 contains the covariances between the elements of y1 and y2. Centering the multivariate normal pdf at zero is a reasonable choice for the estimation of model bias. It means that an unbiased model is a priori regarded as the most likely option.
The posterior pdf is related to the joint distribution by
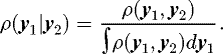 (4)
(4)
The solution for a multivariate normal pdf is another multivariate normal pdf. For equation (3), the result is given by
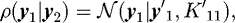 (5)
with the posterior mean vector
(5)
with the posterior mean vector 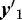 and covariance matrix K'11 (e.g., [[1], A.3]),
and covariance matrix K'11 (e.g., [[1], A.3]),
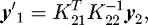 (6)
(6)
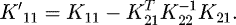 (7)
(7)
The important property of these equations is the fact that the posterior moments depend only on the observed vector y2. The introduction of new elements into y1 and associated columns and rows into K11 in equation (3) has no impact on the already existing values in  and K'11. In other words, one is not obliged to calculate all posterior expectations and covariances at once. They can be calculated sequentially.
and K'11. In other words, one is not obliged to calculate all posterior expectations and covariances at once. They can be calculated sequentially.
GP regression is a method to learn a functional relationship  based on samples of input-output associations {(x1, f1), (x2, f2), … }. The vector y2 introduced above then contains the observed functions values of
based on samples of input-output associations {(x1, f1), (x2, f2), … }. The vector y2 introduced above then contains the observed functions values of 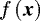 , i.e.
, i.e. 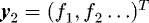 . Assuming all prior expectations to be zero, the missing information to evaluate equations (6) and (7) are the covariance matrices. Because predictions for
. Assuming all prior expectations to be zero, the missing information to evaluate equations (6) and (7) are the covariance matrices. Because predictions for  should be computable at all possible locations x and the same applies to observations, covariances between functions values must be available for all possible pairs
should be computable at all possible locations x and the same applies to observations, covariances between functions values must be available for all possible pairs 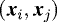 of locations. This requirement can be met by the introduction of a so-called covariance function
of locations. This requirement can be met by the introduction of a so-called covariance function 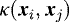 . A popular choice is the squared exponential covariance function
. A popular choice is the squared exponential covariance function
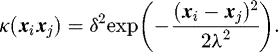 (8)
(8)
The parameter δ enables the incorporation of prior knowledge about the range functions values are expected to span. The parameter λ regulates the smoothness of the solution. The larger λ the slower the covariance function decays for increasing distance between x1 and x2 and consequently the more similar function values are at nearby locations.
If the set 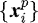 contains the locations of interest and
contains the locations of interest and  the observed locations, the required covariance matrices in equations (6) and (7) are given by
the observed locations, the required covariance matrices in equations (6) and (7) are given by
 (9)
and
(9)
and
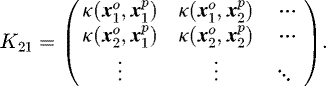 (10)
(10)
2.2 Sparse Gaussian processes
The main hurdle for applying GP regression using many observed pairs (xi, fi) is the inversion of the covariance matrix k22 in equations (6) and (7). The time to invert this N × N matrix with N being the number of observations increases proportional to N3. This limits the application of standard GP regression to several thousand observations on contemporary desktop computers. Parallelization helps to a certain extent to push this limit. Another measure is the approximation of the covariance matrix by a low rank approximation. I adopted the sparse approximation described in [6], which will be briefly outlined here. For a survey of different approaches and their connections consult e.g., [5].
Suppose that we have not measured the values in y2 associated with the locations 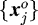 , but instead a vector y3 associated with some other locations
, but instead a vector y3 associated with some other locations 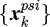 . We refer to y3 as vector of pseudo-inputs. Now we use equation (6) to determine the hypothetical posterior expectation of y2,
. We refer to y3 as vector of pseudo-inputs. Now we use equation (6) to determine the hypothetical posterior expectation of y2,
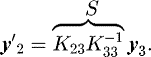 (11)
(11)
The matrices K23 and K33 are constructed analogous to equations (10) and (9), respectively, i.e. 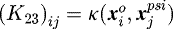 and
and 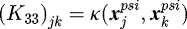 with i = 1..N, j = 1..M and N being the number of observations and M the number of pseudo-inputs. Noteworthy, y'2 is a linear function of y3. Under the assumption of a deterministic relationship, we can replace the posterior expectation y'2 by y2. Using the sandwich formula and
with i = 1..N, j = 1..M and N being the number of observations and M the number of pseudo-inputs. Noteworthy, y'2 is a linear function of y3. Under the assumption of a deterministic relationship, we can replace the posterior expectation y'2 by y2. Using the sandwich formula and  , we get for the covariance matrix of y2
, we get for the covariance matrix of y2
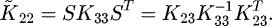 (12)
(12)
Given that both K33 and K23 have full rank and the number of observations N is bigger than the number of pseudo-inputs M, the rank of  equals M. The approximation is more rigid than the original covariance matrix due to the lower rank.
equals M. The approximation is more rigid than the original covariance matrix due to the lower rank.
In order to restore the flexibility of the original covariance matrix, the diagonal matrix 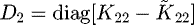 is added to
is added to  . This correction is essential for the determination of the pseudo-input locations via marginal likelihood optimization as explained in [[6], Sect. 3]. Furthermore, to make the approximation exhibit all properties of a GP, it is also necessary to add
. This correction is essential for the determination of the pseudo-input locations via marginal likelihood optimization as explained in [[6], Sect. 3]. Furthermore, to make the approximation exhibit all properties of a GP, it is also necessary to add  to
to 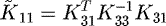 as explained in [[5], Sect. 6].
as explained in [[5], Sect. 6].
Making the replacements  ,
, 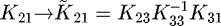 , and
, and  in equations (6) and (7), we obtain
in equations (6) and (7), we obtain
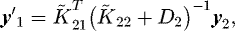 (13)
(13)
 (14)
(14)
Using the Woodbury matrix identity (e.g., [1, A. 3]), these formulas can be rewritten as (e.g.,[5, Sect. 6]),
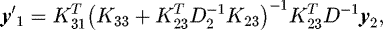 (15)
(15)
 (16)
(16)
Noteworthy, the inversion in these expressions needs only to be performed for an M × M matrix where M is the number of pseudo-inputs. Typically, M is chosen to be in the order of magnitude of hundred. The computational cost for inverting the diagonal matrix D is negligible.
Using equations (15) and (16), the computational complexity scales linearly with the number of observations N due to the multiplication by K23. This feature enables to increase the number of observations by one or two orders of magnitude compared to equations (6) and (7) in typical scenarios.
2.3 Marginal likelihood maximization
Covariance functions depend on parameters (called hyperparamters) whose values must be specified. In a full Bayesian treatment, the choice of values should not be informed by the same observations that enter into the GP regression afterwards. In practice, this ideal is often difficult to achieve due to the scarcity of available data and therefore frequently abandoned. A full Bayesian treatment may also become computationally intractable if there are too much data.
Two popular approaches to determine the hyperparameters based on the data are marginal likelihood maximization and cross validation, see e.g., [1, Chap. 5]. A general statement which approach performs better cannot be made. I decided to use marginal likelihood optimization because it can probably be easier interfaced with existing nuclear data evaluation methods.
Given a covariance function depending on some hyperparameters, e.g., κ(xi, xj2|δ, λ) with hyperparameters δ and λ as in equation (8), the idea of marginal likelihood maximization is to select values for the hyperparameters that maximize the probability density for the observation vector ρ(y2). In the case of the multivariate normal pdf in equation (3), it is given by (e.g., [1, Sect. 5.4.1)
 (17)
(17)
The first term is a constant, the second term is up to a constant the information entropy of the multivariate normal distribution, and the third term is the generalized χ2-value. The maximization of this expression amounts to balancing two objectives: minimizing the information entropy and maximizing the χ2-value.
The partial derivative of equation (17) with respect to a hyperparameter is given by (e.g., [[1], Sect. 5.4.1)
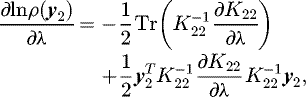 (18)
which enables the usage of gradient-based optimization algorithms. In this paper, I use the L-BFGS-B algorithm [15] because it can deal with a large number of parameters and allows to impose restrictions on their ranges.
(18)
which enables the usage of gradient-based optimization algorithms. In this paper, I use the L-BFGS-B algorithm [15] because it can deal with a large number of parameters and allows to impose restrictions on their ranges.
Due to the appearance of the determinant and the inverse of K22, the optimization is limited to several thousand observations on contemporary desktop computers. However, replacing K22 by the approximation  in equations (17) and (18) enables to scale up the number of observations by one or two orders of magnitude. The structure of the approximation is exploited by making use of the matrix determinant lemma, the Woodbury identity, and the trace being invariant under cyclic permutations.
in equations (17) and (18) enables to scale up the number of observations by one or two orders of magnitude. The structure of the approximation is exploited by making use of the matrix determinant lemma, the Woodbury identity, and the trace being invariant under cyclic permutations.
The approximation to K22 is not only determined by the hyperparameters but also by the location of the pseudo-inputs 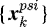 . Hyperparameters and pseudo-input locations can be jointly adjusted by marginal likelihood maximization. The number of pseudo-inputs is usually significantly larger (e.g., hundreds) than the number of hyperparameters (e.g., dozens). In addition, the pseudo-inputs are points in a potentially multi-dimensional space and their specification requires a coordinate value for each axis. For instance, in Section 3 sparse GP regression is performed in a five dimensional space with three hundred pseudo-inputs, which gives 1500 associated parameters. Because equation (18) has to be evaluated for each parameter in each iteration of the optimization algorithm, its efficient computation is important.
. Hyperparameters and pseudo-input locations can be jointly adjusted by marginal likelihood maximization. The number of pseudo-inputs is usually significantly larger (e.g., hundreds) than the number of hyperparameters (e.g., dozens). In addition, the pseudo-inputs are points in a potentially multi-dimensional space and their specification requires a coordinate value for each axis. For instance, in Section 3 sparse GP regression is performed in a five dimensional space with three hundred pseudo-inputs, which gives 1500 associated parameters. Because equation (18) has to be evaluated for each parameter in each iteration of the optimization algorithm, its efficient computation is important.
The mathematical details are technical and tedious and hence only the key ingredient for efficient computation will be discussed. Let xkl be the lth coordinate of the kth pseudo-input. The crucial observation is that ∂K33/∂ xkl yields a matrix in which only the lth and kth column and row contain non-zero elements. A similar statement holds for ∂K23/∂ xkl. This feature can be exploited in the multiplications and the trace computation in equation (18) (where K22 is substituted by 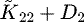 ) to achieve
) to achieve  per coordinate of a pseudo-input with M being the number of pseudo-inputs, and N being the number of observations. This is much more efficient than
per coordinate of a pseudo-input with M being the number of pseudo-inputs, and N being the number of observations. This is much more efficient than 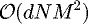 for the partial derivative with respect to a hyperparameter.
for the partial derivative with respect to a hyperparameter.
3 Application
3.1 Scenario
The model bias was determined for the C++ version of the Liège INCL [7], a Monte Carlo code, coupled to the evaporation code ABLA07 [9] because this model combination performs very well according to an IAEA benchmark of spallation models [16,17] and is used in transport codes such as MCNPX and GEANT4. This suggests that the dissemination of a more quantitative performance assessment of INCL coupled to ABLA potentially helps many people to make better informed decisions. Because some model ingredients in INCL are based on views of classical physics (as opposed to quantum physics), the model is mainly used for high-energy reactions above 100 MeV.
The ability of a model to accurately predict the production of neutrons and their kinematic properties may be regarded as one of the most essential features for nuclear engineering applications. Especially for the development of the innovative research reactor MYRRHA [18] driven by a proton accelerator, these quantities need to be well predicted for incident protons.
For these reasons, I applied the approach to determine the model bias in the prediction of inclusive double-differential neutron spectra for incident protons and included almost all nuclei for which I found data in the EXFOR database [10]. Roughly ten thousand data points were taken into account. Table 1 gives an overview of the data.
Summary of the double-differential (p,X)n data above 100 MeV incident energy found in EXFOR [10]. No mass number is appended to the isotope name in the case of natural composition. Columns are: incident proton energy (En), range of emitted neutron energy (Emin, Emax), range of emission angles (θmin, θmax), and number of data points (NumPts). Energy related columns are in MeV and angles in degree. The total number of data points is 9287.
3.2 Design of the covariance function
The covariance function presented in equation (8) is probably too restrictive to be directly used on double-differential spectra. It incorporates the assumption that the model bias spans about the same range for low and high emission energies. Because the neutron spectrum quickly declines by orders of magnitude with increasing emission energy, it is reasonable to use a covariance function with more flexibility to disentangle the systematics of the model bias associated with these two energy domains.
Assuming the two covariance functions κ1(xi, xj) and κ2(xi, xj), a more flexible covariance function can be constructed in the following ways (e.g., [1, Sect. 4.2.4])
 (19)
(19)
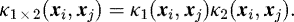 (20)
(20)
Taking into account that the purpose of a covariance function is to compute elements of a covariance matrix, the construction in equation (19) is analogous to the possible construction of an experimental covariance matrix: An experimental covariance matrix can be assembled by adding a diagonal covariance matrix reflecting statistical uncertainties to another one with systematic error contributions. Please note that sparse GP regression as presented in this paper works only with a diagonal experimental covariance matrix. Equation (20) will be used to achieve a transition between the low and high energy domains.
To state the full covariance function used in this paper, the following covariance function on a one-dimensional input space is introduced,
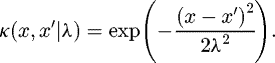 (21)
(21)
The meaning of the hyperparameter λ was explained below equation (8).
The inclusive double-differential neutron spectra for incident protons over the complete nuclide chart can be thought of as a function of spectrum values associated with points in a five dimensional input space. The coordinate axes are incident energy (En), mass number (A), charge number (Z), emission angle (θ) and emission energy (E). Using equation (21) we define two covariance functions κL and κH associated with the low and high energy domain of the emitted neutrons. Given two input vectors
 (22)
(22)
 (23)
the form of the covariance function for both κL and κH is assumed to be
(23)
the form of the covariance function for both κL and κH is assumed to be
 (24)
(24)
The hyperparameters 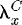 are for the coordinate axis indicated by x ∈ {En, A, …} and can take different values for κL and κH (C ∈ {L, H}).
are for the coordinate axis indicated by x ∈ {En, A, …} and can take different values for κL and κH (C ∈ {L, H}).
The transition between the two energy domains, which means to switch from κL to κH, is established by the logistic function
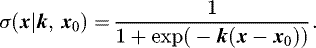 (25)
(25)
Noteworthy, all the variables are vectors. The equation  defines a (hyper)plane with normal vector k and distance
defines a (hyper)plane with normal vector k and distance 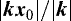 to the origin of the coordinate system. The function in equation (25) attains values close to zero for x far away from the plane on one side and close to one if far away on the other side. Within which distance to the plane the transition from zero to one occurs depends on the length of k. The larger |k|, the faster the transition and the narrower the window of transition around the plane.
to the origin of the coordinate system. The function in equation (25) attains values close to zero for x far away from the plane on one side and close to one if far away on the other side. Within which distance to the plane the transition from zero to one occurs depends on the length of k. The larger |k|, the faster the transition and the narrower the window of transition around the plane.
With the abbreviations
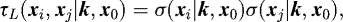 (26)
(26)
 (27)
(27)
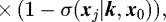 (28)
the full covariance function κfull is given by
(28)
the full covariance function κfull is given by
 (29)
(29)
Finally, the GP regression is not performed on the absolute difference Δ between a model prediction σmod and experimental data point σexp, but on the transformed quantity
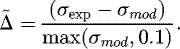 (30)
(30)
In words, relative differences are taken for model predictions larger than 0.1 and absolute differences scaled up by a factor of ten for model predictions below 0.1. Relative differences fluctuate usually wildly for spectrum values close to zero–especially for a Monte Carlo code such as INCL–and the switch to absolute values helps GP regression to find more meaningful solutions with a better ability to extrapolate.
Due to the number of roughly ten thousand data points, the covariance matrices computed with equation (29) were replaced by the sparse approximation outlined in Section 2.2. I introduced three hundred pseudo-inputs and placed them randomly at the locations of the experimental data. Their locations were then jointly optimized with the hyperparameters, which will be discussed in Section 3.3.
The diagonal matrix D2 occurring in the approximation was changed to
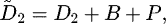 (31)
to accommodate statistical uncertainties of the model prediction (due to INCL being a Monte Carlo code) and the experimental data. Both B and P are diagonal matrices. The matrix B contains variances corresponding to 10% statistical uncertainty for all experimental data points. The matrix P contains the estimated variances of the model predictions.
(31)
to accommodate statistical uncertainties of the model prediction (due to INCL being a Monte Carlo code) and the experimental data. Both B and P are diagonal matrices. The matrix B contains variances corresponding to 10% statistical uncertainty for all experimental data points. The matrix P contains the estimated variances of the model predictions.
A diagonal matrix for the experimental covariance matrix B can certainly be challenged because the important systematic errors of experiments reflected in off-diagonal elements are neglected. This is at the moment a limitation of the approach.
3.3 Marginal likelihood maximization
The hyperparameters appearing in equation (29) and the locations of the three hundred pseudo-inputs 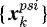 determining the approximation in equation (11) were adjusted via marginal likelihood maximization described in Section 2.3. To be explicit, the hyperparameters considered were δL, δH,
determining the approximation in equation (11) were adjusted via marginal likelihood maximization described in Section 2.3. To be explicit, the hyperparameters considered were δL, δH,
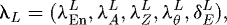 (32)
(32)
 (33)
and also x0 and k of the logistic function. The vector k was forced to remain parallel to the axes associated with En, A, and Z, i.e.
(33)
and also x0 and k of the logistic function. The vector k was forced to remain parallel to the axes associated with En, A, and Z, i.e. 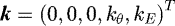 . Further, polar coordinates kθ = kcsinγ, kE = kccosγ were introduced. The direction of the vector x0 was taken equal to that of k, which removes ambiguity in the plane specification without shrinking the set of possible solutions. Because of these measures, it sufficed to consider the length xc = |x0| as hyperparameter. Counting both hyperparameters and pseudo-inputs, 1515 parameters were taken into account in the optimization.
. Further, polar coordinates kθ = kcsinγ, kE = kccosγ were introduced. The direction of the vector x0 was taken equal to that of k, which removes ambiguity in the plane specification without shrinking the set of possible solutions. Because of these measures, it sufficed to consider the length xc = |x0| as hyperparameter. Counting both hyperparameters and pseudo-inputs, 1515 parameters were taken into account in the optimization.
I employed the L-BFGS-B algorithm [15] as implemented in the optim function of R [19], which makes use of an analytic gradient, can deal with a large number of variables and permits the specification of range restrictions. The optimization was performed on a cluster using 25 cores and was stopped after 3500 iterations, which took about 10 h. The obtained solution corresponds to χ2/N = 1.03 and is with a two-sided p-value of 0.04 reasonably consistent in a statistical sense. Restrictions of parameter ranges were established to introduce prior knowledge and to guide the optimization procedure. Noteworthy, lower limits on length-scales, such as 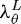 and
and  ; were introduced to counteract their dramatic reduction due to inconsistent experimental data in the same energy/angle range. Table 2 summarizes the optimization procedure. The evolution of the pseudo-inputs projected onto the (A,Z)-plane is visualized in Figure 1.
; were introduced to counteract their dramatic reduction due to inconsistent experimental data in the same energy/angle range. Table 2 summarizes the optimization procedure. The evolution of the pseudo-inputs projected onto the (A,Z)-plane is visualized in Figure 1.
Setup of the L-BFGS-B optimization and evolution of hyperparameters. The columns LB and UB give the lower bound and upper bound, respectively, of the parameter ranges. Columns It indicate the parameter values after i × 1000 iterations. The column It0 contains initial values and Itf the final values after 3500 iterations.
 |
Fig. 1 Dispersion of the pseudo-inputs during the optimization procedure shown in the (A,Z)-projection. The black points are the initial positions and the green points the final positions of the pseudo-inputs. |
A thorough study of the optimization process exceeds the scope of this paper and hence I content myself with a few remarks. The length scales associated with the emission angle, i.e.  , experienced significant changes. Their increase means that the model bias is similar for emission angles far away from each other and the GP process is able to capture them. Concerning the length scales associated with the emission energy, the small value
, experienced significant changes. Their increase means that the model bias is similar for emission angles far away from each other and the GP process is able to capture them. Concerning the length scales associated with the emission energy, the small value  compared to the larger value
compared to the larger value 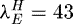 indicates that the features of the model bias of the low and high energy domain are indeed different. The most striking feature, however, is that the large length scales
indicates that the features of the model bias of the low and high energy domain are indeed different. The most striking feature, however, is that the large length scales  and
and  “survived” the optimization, which means that the model bias behaves similar over large regions of the nuclide charts. Examples of isotope extrapolations will be given in Section 3.4.
“survived” the optimization, which means that the model bias behaves similar over large regions of the nuclide charts. Examples of isotope extrapolations will be given in Section 3.4.
As a final remark, a more rigorous study of the optimization procedure is certainly necessary and there is room for improvement. This is left as future work.
3.4 Results and discussion
The values of the hyperparameters and pseudo-inputs obtained by marginal likelihood maximization were used in the covariance function in equation (29). This covariance function was employed to compute the required covariance matrices in equations (15) and (16) based on the experimental data summarized in Table 1. Because the hyperparameters are determined during hyperparameter optimization before being used in the GP regression, they will be referred to as prior knowledge.
Equations (15) and (16) enable the prediction of a plethora of spectrum values and their uncertainties for combinations of incident energy, mass number, charge number, emission angle, and emission energy. The few selected examples of predictions in Figure 2 serve as the basis to discuss general features of GP regression, the underlying assumptions, and its accuracy and validity.
How well we can interpolate between data and how far we can extrapolate beyond the data depends on the suitability of the covariance function for the problem at hand. The building block for the full covariance function in equation (29) is the one-dimensional covariance function in equation (21). Using the latter imposes the assumption that possible solutions have derivatives of any order and hence are very smooth [1, Chap. 4]. Interpolations between data points included in the regression are determined by this smoothness property and values of the length scales  .
.
The length scales reflect the prior assumption about similarity between spectrum values of points a certain distance away from each other. This prior assumption directly impacts the uncertainty of the predictions. The farther away a prediction is from an observation point, the higher the associated uncertainty. If a prediction is already multiples of any length scale away from all observations, the uncertainty reverts to its prior value given by either δL or δH depending on the energy domain.
In the case of the sparse approximation, the uncertainty is related to the distance to the pseudo-inputs. Because only few pseudo-inputs are located at very high and very low emission energies, the 2σ uncertainty bands in Figure 2 in those energy domains are rather large despite the presence of experimental data.
The important finding in this specific application is that the length scales related to emission angle, 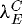 , mass number,
, mass number, 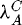 , and charge number,
, and charge number, 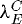 , are very large. GP regression is therefore able to interpolate and extrapolate over large ranges of these axes.
, are very large. GP regression is therefore able to interpolate and extrapolate over large ranges of these axes.
The interpolation of spectrum values between angles and emission energies of an isotope with available data may be considered rather standard. For instance, one can do a χ2-fit of a low order Legendre polynomial to the angular distributions for emission energies with data. The coefficients of the Legendre polynomial for intermediate emission energies without data can then be obtained by linear interpolation.
The important difference between such a conventional fit and GP regression is the number of basis functions. Whereas their number is fixed and limited in a conventional fit, GP regression amounts to a fit with an infinite number of basis functions [1, Sect. 2.2]. The length scales regulate the number of basis functions that effectively contribute to the solution. Hyperparameter optimization decreases the length scales for unpredictable data which leads to a greater number of contributing basis functions and consequently to greater flexibility and larger uncertainties in the predictions. This feature sets GP regression apart from a standard χ2-fit. In the latter, the uncertainty of the solution depends to a much lesser extent on the (un)predictability of the data and much more on the number of data points and the fixed number of basis functions.
One truly novel element in the approach is the inclusion of the mass and charge number, which enables predictions for isotopes without data. We can easily imagine that different isotopes differ significantly by their physical properties. From this perspective, the idea to extrapolate the model bias to other isotopes should be met with healthy skepticism.
To get a first grasp on the validity of isotope extrapolations, let us consider again the hyperparameter optimization discussed in Section 3.3. The hyperparameters were adjusted on the basis of the isotopes in Table 1. These data are spread out over the periodic table and cover a range from carbon to thorium. In these data, similar trends of the model bias persist across significant ranges of the mass and charge number, which was the reason that the associated length scales retained high values during optimization. For instance, the experimental data of carbon and indium in Figure 2 show comparable structures of the model bias despite their mass differences.
However, the isotopes considered in the optimization are not very exotic and gaps between them are at times large. Further, these isotopes are certainly not a random sample taken from the periodic table and therefore most theoretical guarantees coming from estimation theory do not hold. So how confident can we be about isotope extrapolation?
To provide a basis for the discussion of this question, Figure 2 also contains predictions for oxygen and cadmium. Importantly, the associated experimental data have not been used for the hyperparameter optimization and in the GP regression. The predictions follow well the trend of the experimental data. The supposedly 2σ uncertainty bands, however, include less than 95% of the data points. This observation points out that there are systematic differences between isotopes. Therefore, due to the sample of isotopes not being a random sample, uncertainty bands should be interpreted with caution.
One way to alleviate this issue could be to add a covariance function to equation (29) which only correlates spectrum values of the same isotope but not between isotopes. This measure would lead to an additional uncertainty component for each isotope, which only decreases if associated data are included in the GP regression.
A very extreme mismatch up to 500% between the prediction and experimental data occurs for oxygen at 60° and emission energies below 1 MeV. The creation of low energy neutrons is governed by de-excitation processes of the nucleus suggesting that the angular distribution of emitted particles is isotropic. This property holds for the model predictions but not for the experimental data. The experimental data exhibits a peak at 60° which is about a factor five higher than at 30°, 120° and 150°. The origin of this peculiarity may deserve investigation but is outside the scope of this work. For the sake of argument I assume that it is indeed a reflection of some property of the nucleus.
Because the data in Table 1 do not include any measurements below 1 MeV emission energy in this mass range, both hyperparameter optimization and GP regression had no chance to be informed about such a feature. In this case, the predictions and uncertainties are determined by nearby values or – if there are not any – by the prior expectation.
If we would have been aware of such effects, we could have used it as a component in the covariance function to reflect our large uncertainty about the spectrum for low emission energies. Otherwise, the only sensible data-driven way to provide predictions and uncertainties for unobserved domains is to assume that effects are similar to those in some observed domains. Of course, it is our decision which domains are considered similar. The employed covariance function in equation (29) incorporates the assumption that nearby domains in terms of mass charge, angle, etc. are similar. However, we are free to use any other assumption about similarity to construct the covariance function. As a side note, also results of other models relying on different assumptions could serve as a basis for uncertainties in unobserved regions. Such information can be included in GP regression in a principled way.
 |
Fig. 2 Model bias of INCL in terms of equation (30) in the (p,X)n double differential spectra for 800 MeV incident protons and different isotopes as predicted by GP regression. A missing mass number behind the isotope symbol indicates natural composition. The uncertainty band of the prediction and the error bars of the experimental data denote the 2σ confidence interval. Carbon and indium were taken into account in the GP regression but not cadmium and oxygen. The experimental data are colored according to the associated access number (ACCNUM) in the EXFOR database. This shows that all displayed data come from just three experiments [20–22]. |
4 Summary and outlook
Sparse GP regression, a non-parametric estimation technique of statistics, was employed to estimate the model bias of the C++ version of the Liège INCL coupled to the evaporation code ABLA07. Specifically, the model bias in the prediction of double-differential inclusive neutron spectra over the complete nuclide chart was investigated for incident protons above 100 MeV. Experimental data from the EXFOR database served as the basis of this assessment. Roughly ten thousand data points were taken into account. The hyperparameter optimization was done on a computing cluster whereas the GP regression itself on a desktop computer. The obtained timings indicate that increasing the number of data points by a factor of ten could be feasible.
For this specific application, it was shown that GP regression produces reasonable results for isotopes that have been included in the procedure. It was argued that the validity of predictions and uncertainties for isotopes not used in the procedure depends on the validity of the assumptions made about similarity between isotopes. As a simple benchmark, the isotopes oxygen and cadmium, which have not been taken into account in the procedure, were compared to the respective predictions. The agreement between prediction and experimental data was reasonable but the 95% confidence band sometimes misleading and should therefore be interpreted with caution. Accepting the low energy peak of oxgyen at 60° in the data as physical reality, the low energy spectrum of oxygen served as an example where the similarity assumption between isotopes did not hold.
As for any other uncertainty quantification method, it is a hard if not impossible task to properly take into account unobserved phenomena without any systematic relationship to observed ones. The existence of such phenomena are unknown unknowns, their observation is tagged shock, surprise or discovery, and they potentially have a huge impact where they appear.
Even though GP regression cannot solve the philosophical problem associated with unknown unknowns, knowledge coming from the observation of new effects can be taken into account by modifying the covariance function. For instance, the peculiar peak in the oxygen spectrum suggests the introduction of a term in the covariance function which increases the uncertainty of the spectrum values in the low emission energy domain. The ability to counter new observations with clearly interpretable modifications of the covariance function represents a principled and transparent way of knowledge acquisition.
The scalability and the possibility to incorporate prior assumptions by modeling the covariance function makes sparse GP regression a promising candidate for global assessments of nuclear models and to quantify their uncertainties. Because the formulas of GP regression are structurally identical to those of many existing evaluation methods, GP regression should be regarded more as a complement than a substitute, which can be interfaced with existing evaluation methods.
Acknowledgments
This work was performed within the work package WP11 of the CHANDA project (605203) financed by the European Commission. Thanks to Sylvie Leray, Jean-Christophe David and Davide Mancusi for useful discussion.
References
- C.E. Rasmussen, C.K.I. Williams, Gaussian Processes for Machine Learning (MIT Press, Cambridge, Mass., 2006) [Google Scholar]
- D.W. Muir, A. Trkov, I. Kodeli, R. Capote, V. Zerkin, The Global Assessment of Nuclear Data, GANDR (EDP Sciences, 2007) [Google Scholar]
- H. Leeb, D. Neudecker, T. Srdinko, Nucl. Data Sheets 109, 2762 (2008) [CrossRef] [Google Scholar]
- M. Herman, M. Pigni, P. Oblozinsky, S. Mughabghab, C. Mattoon, R. Capote, Y.S. Cho, A. Trkov, Tech. Rep. BNL-81624-2008-C P, Brookhaven National Laboratory, 2008 [Google Scholar]
- J. Quiñonero-Candela, C.E. Rasmussen, J. Mach. Learn. Res. 6, 1939 (2005) [Google Scholar]
- E. Snelson, Z. Ghahramani, Sparse Gaussian Processes Using Pseudo-Inputs, in Advances in Neural Information Processing Systems (2006), pp. 1257–1264 [Google Scholar]
- D. Mancusi, A. Boudard, J. Cugnon, J.C. David, P. Kaitaniemi, S. Leray, New C++ Version of the Liège Intranuclear Cascade Model in Geant4 (EDP Sciences, 2014), p. 05209 [Google Scholar]
- D. Mancusi, A. Boudard, J. Cugnon, J.C. David, P. Kaitaniemi, S. Leray, Phys. Rev. C 90, 054602 (2014) [CrossRef] [Google Scholar]
- A. Kelic, M.V. Ricciardi, K. H. Schmidt (2009) [Google Scholar]
- N. Otuka, E. Dupont, V. Semkova, B. Pritychenko, A. Blokhin, M. Aikawa, S. Babykina, M. Bossant, G. Chen, S. Dunaeva et al., Nucl. Data Sheets 120, 272 (2014) [CrossRef] [Google Scholar]
- B.J.N. Blight, L. Ott, Biometrika 62, 79 (1975) [CrossRef] [Google Scholar]
- M.T. Pigni, H. Leeb, Uncertainty estimates of evaluated 56fe cross sections based on extensive modelling at energies beyond 20 MeV, in Proc. Int. Workshop on Nuclear Data for the Transmutation of Nuclear Waste. GSI-Darmstadt, Germany (2003) [Google Scholar]
- G. Schnabel, Ph.D. thesis, Technische Universität Wien, Vienna, 2015 [Google Scholar]
- G. Schnabel, H. Leeb, EPJ Web Conf. 111, 09001 (2016) [CrossRef] [EDP Sciences] [Google Scholar]
- R.H. Byrd, P. Lu, J. Nocedal, C. Zhu, SIAM J. Sci. Comput. 16, 1190 (1995) [Google Scholar]
- IAEA benchmark 2010, https://www-nds.iaea.org/spallations/ [Google Scholar]
- J.C. David, Eur. Phys. J. A 51, 68 (2015) [CrossRef] [Google Scholar]
- MYRRHA: An innovative research installation, http://sckcen.be/en/Technology_future/MYRRHA [Google Scholar]
- R Development Core Team, R: A Language and Environment for Statistical Computing (R Foundation for Statistical Computing, Vienna, Austria, 2008) [Google Scholar]
- W.B. Amian, R.C. Byrd, C.A. Goulding, M.M. Meier, G.L. Morgan, C.E. Moss, D.A. Clark, Nucl. Sci. Eng. 112, 78 (1992) [CrossRef] [Google Scholar]
- T. Nakamoto, K. Ishibashi, N. Matsufuji, N. Shigyo, K. Maehata, S.I. Meigo, H. Takada, S. Chiba, M. Numajiri, T. Nakamura et al., J. Nucl. Sci. Technol. 32, 827 (1995) [CrossRef] [Google Scholar]
- K. Ishibashi, H. Takada, T. Nakamoto, N. Shigyo, K. Maehata, N. Matsufuji, S.I. Meigo, S. Chiba, M. Numajiri, Y. Watanabe et al., J. Nucl. Sci. Technol. 34, 529 (1997) [CrossRef] [Google Scholar]
Cite this article as: Georg Schnabel, Estimating model bias over the complete nuclide chart with sparse Gaussian processes at the example of INCL/ABLA and double-differential neutron spectra, EPJ Nuclear Sci. Technol. 4, 33 (2018)
All Tables
Summary of the double-differential (p,X)n data above 100 MeV incident energy found in EXFOR [10]. No mass number is appended to the isotope name in the case of natural composition. Columns are: incident proton energy (En), range of emitted neutron energy (Emin, Emax), range of emission angles (θmin, θmax), and number of data points (NumPts). Energy related columns are in MeV and angles in degree. The total number of data points is 9287.
Setup of the L-BFGS-B optimization and evolution of hyperparameters. The columns LB and UB give the lower bound and upper bound, respectively, of the parameter ranges. Columns It indicate the parameter values after i × 1000 iterations. The column It0 contains initial values and Itf the final values after 3500 iterations.
All Figures
|
Fig. 1 Dispersion of the pseudo-inputs during the optimization procedure shown in the (A,Z)-projection. The black points are the initial positions and the green points the final positions of the pseudo-inputs. |
| In the text | |
|
Fig. 2 Model bias of INCL in terms of equation (30) in the (p,X)n double differential spectra for 800 MeV incident protons and different isotopes as predicted by GP regression. A missing mass number behind the isotope symbol indicates natural composition. The uncertainty band of the prediction and the error bars of the experimental data denote the 2σ confidence interval. Carbon and indium were taken into account in the GP regression but not cadmium and oxygen. The experimental data are colored according to the associated access number (ACCNUM) in the EXFOR database. This shows that all displayed data come from just three experiments [20–22]. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.